얼마전 저희 회사 프로젝트에서 내부 문서(정책, 매뉴얼, 제품 스펙)를 기반으로 고객 질의에 답하는 RAG 서비스를 만들었습니다. 초기에는 단일 임베딩 검색만 사용했는데, 특정 고유명사나 법조문과 같이 정밀한 매칭이 필요한 질의에서 오답이 많이 나왔습니다. 이 문제를 해결하기 위해 시맨틱 검색과 키워드 검색을 혼합한 Hybrid Search를 도입했고, 추가로 문서를 ‘질문형’으로 변환하는 방법(Hypothetical Question)과 쿼리로부터 가상 문서를 생성해 임베딩 비교하는 HyDE를 실험적으로 적용해 짧은 기간에 정확도가 눈에 띄게 개선되는 것을 확인했습니다. 이러한 실험을 통해 얻은 인사이트가 곧 제가 생각하는 RAG의 핵심 기술입니다.
RAG란 무엇인가?
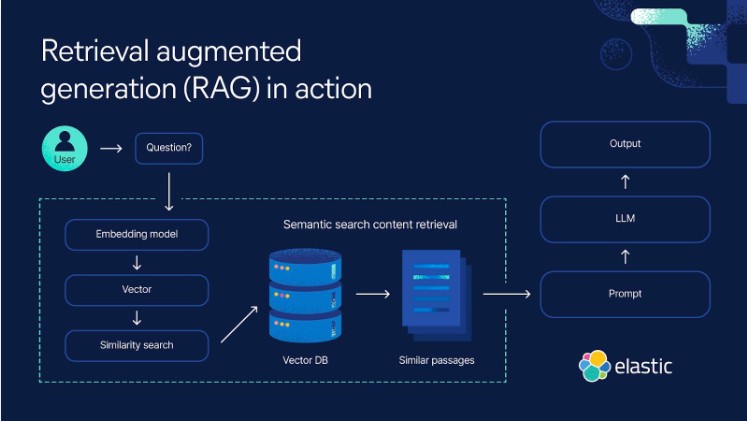
RAG를 실제 프로젝트에 적용해보니 LLM의 한계를 가장 효과적으로 보완하는 기술이라는 걸 확실히 느꼈습니다. LLM만 사용할 때는 최신 정보 부족, 특정 도메인 지식 오류, 긴 문맥 유지 문제, 편향된 답변 등 여러 제약이 있었는데, RAG는 외부 문서를 검색해 답변을 생성하기 때문에 정보의 정확성과 신뢰도가 크게 올라갔습니다. 또한 필요한 정보만 불러오니 모델을 과도하게 키울 필요도 없고 속도와 비용 측면에서도 효율적이었습니다. 다양한 출처 기반이라 편향도 줄고 답변 근거가 명확해져 실제 서비스 품질이 확실히 개선되었습니다.
Hybrid Search — 시맨틱 + 키워드, 언제 가중치를 조정해야 하나
개념을 요약해보자면, 의미 기반 임베딩 검색(semantic embeddings)과 전통적 키워드 검색(BM25, Elasticsearch term query 등)을 결합해 후보 문서를 추출합니다.
언제 효과적인가?
사용자 질의에 고유명사·코드·조항이 포함될 때
짧은 쿼리(예: 제품 모델명, 법령 번호)에서 정확한 패턴 매칭이 필요할 때
실무 팁
검색 점수는 보통 score = α * semantic_score + (1-α) * bm25_score 형태로 합칩니다. α는 0.6~0.8로 시작해 A/B 테스트로 조정하세요.
문서 길이·섹션 중요도(메타데이터)를 가중치로 넣어 후보 순위를 안정화합니다.
벤치마크 지표: recall@k, MRR를 사용해 α 값과 후보 수를 튜닝합니다.
Hypothetical Question — 문서를 ‘질문’으로 바꿔 매칭률 끌어올리기
기존 문서의 핵심 문장을 자동으로 질문 형태로 변환해, 사용자 쿼리와 질문의 의미적 유사도를 비교하는 방식입니다.
왜 유용한가? 문서와 쿼리가 서로 다른 표현을 쓰는 경우(예: 설명형 문장 vs. 질의형 문장) 의미적 매칭을 높여 줍니다. 간접적 표현 또는 복잡한 의도를 가진 쿼리에서 특히 효과가 큽니다.
실무 팁
문서 인덱싱 시 주요 문단을 미리 Q-A 형태로 변환해 별도 인덱스로 저장하면 실시간 변환 비용을 줄일 수 있습니다. 변환 모델의 품질에 민감하므로, 질문 생성 시 온도(temperature)를 낮게 고정하고 규칙 기반 후처리를 추가해 이상 질문을 필터링하세요.
Hypothetical Question은 HyDE와 결합하면 더 강력합니다(다음 항목 참조).
HyDE (Hypothetical Document Embeddings) — 쿼리 → 가상 문서 → 임베딩 비교
사용자의 쿼리로 LLM이 ‘가상의 답변/문서’를 생성하고, 이 가상 문서의 임베딩과 실제 문서 임베딩을 비교해 관련 문서를 찾는 방식입니다.
장점
짧거나 불명확한 쿼리의 의미를 확장해 풍부한 컨텍스트를 만듭니다. 직접 질의에 대한 가설적 응답을 생성하므로 임베딩 공간에서 문서와의 의미적 유사도가 더 명확해집니다.
실무 팁
HyDE 생성은 비용이 들므로 후보 수를 줄인 후(예: BM25 상위 200개) 적용하는 단계적 파이프라인이 효율적입니다. 생성 모델의 온도를 낮게 해 “사실형” 응답을 유도하면 노이즈를 줄일 수 있습니다. HyDE의 가상 문서는 문서 요약과 결합해 재랭킹(reranking)에 사용하면 안정성이 증가합니다.
통합 전략 실제 파이프라인 예시
- 사용자 쿼리 수신
- 빠른 키워드 검색(BM25)로 후보 200개 수집
- 임베딩 기반 시맨틱 검색으로 후보 200개 추가 → Hybrid 합산(α 조정) → 후보 100개 선정
- 후보에서 Hypothetical Question(문서→질문)과 HyDE(쿼리→가상문서) 적용해 의미적 유사도 재계산
- 상위 5~10개 문서를 LLM 컨텍스트로 제공해 생성 모델에서 최종 응답 생성 및 근거 제시
평가와 안전장치
- 정확성 평가 : recall@k, MRR, precision@k으로 정량적 비교를 수행했습니다. 실무에서는 A/B 테스트로 유저 만족도를 함께 측정하세요.
- 출처 추적 : RAG 응답은 반드시 근거(문서 ID, 인용 문장)를 함께 반환해 검증 가능하도록 구성해야 신뢰도가 높아집니다.
- 편향, 위조 방지 : HyDE 같은 생성 기반 기법은 가끔 허위 근거를 만들 수 있으니, 생성물과 원문 간의 질적 일치 검사를 추가하세요.
RAG의 핵심 기술을 실무에 적용하는 태도
제가 직접 여러 프로젝트를 경험해보며 얻은 결론은 단순히 한 기술을 적용하는 것이 아니라, Hybrid Search로 넓게 후보를 모으고, Hypothetical Question과 HyDE로 의미적 문맥을 보강해 단계적으로 좁혀가는 ‘파이프라인 설계’가 성능을 좌우한다는 점입니다. 이 조합은 검색의 정밀도와 생성 응답의 신뢰성을 동시에 끌어올려 실제 서비스에서의 문제를 효과적으로 줄여줍니다.
RAG를 도입하거나 고도화하려는 팀이라면, 본문에서 제시한 실무 팁이나 가중치 튜닝, 전처리·후처리, 평가 지표 설계등을 차근차근 적용해 보시면 도움이 될것입니다. 이것이 바로 제가 경험으로 확신하는 RAG의 핵심 기술 실전 적용법입니다. 누군가에게는 도움이 되는 자료가 되었으면 합니다.
느낀점 정리
정리하자면, 실제로 RAG를 여러 번 구축해보면서 느낀 것은 LLM이 가진 한계를 직접적으로 보완해주는 가장 실용적인 접근법이라는 점입니다. 최신성·정확성·효율성·투명성이라는 네 가지 문제를 한 번에 해결해 주기 때문에, 지금은 대부분의 실무 프로젝트에서 기본 옵션처럼 RAG를 채택하고 있습니다. LLM만으로 성능을 억지로 끌어올리던 시절에는 돌아갈 수 없을 만큼, RAG의 효용은 생각보다 훨씬 컸습니다.